 FreeOCR è un programma per convertire il testo presente su un'immagine in testo editabile, un esempio; si digitalizza le pagine di un libro con uno scanner e poi le immagini si convertono in testo con un programma OCR. FreeOCR non ha le funzioni di un programma professionale, ma fa bene il suo lavoro. Disponibile anche il dizionario Italiano.
FreeOCR è un programma per convertire il testo presente su un'immagine in testo editabile, un esempio; si digitalizza le pagine di un libro con uno scanner e poi le immagini si convertono in testo con un programma OCR. FreeOCR non ha le funzioni di un programma professionale, ma fa bene il suo lavoro. Disponibile anche il dizionario Italiano.
Ultima versione ha tutto in un unico file di installazione.
Decomprimiamo il file zip sul desktop, verrà estratto una cartella con il nome FreeOCR, entriamo nella cartella e lanciamo il programma freeocr.exe
durante l'installazione dobbiamo essere connessi a internet, il programma pesa appena 156 Kb, da internet scaricherà circa 3 Mb di dati
clicchiamo su Next
accettiamo la licenza e clicchiamo su Next
clicchiamo su Install
clicchiamo su Finish
clicchiamo sull'icona nel desktop o nel menu programmi di windows
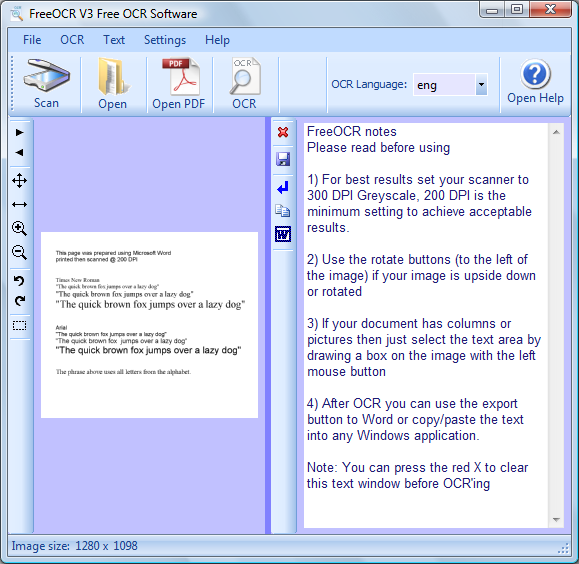
questa è la finestra del programma, si può ingrandire a tutto schermo
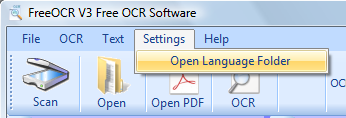
prima operazione, installare il dizionario Italiano, andiamo nel menu Settings e spuntiamo Open Language Folder
il programma è solo in inglese, il dizionario Italiano serve per il riconoscimento delle parole nella nostra lingua per non segnalarle come errore
si aprirà la cartella dei dizionari, lasciamo aperta questa cartella
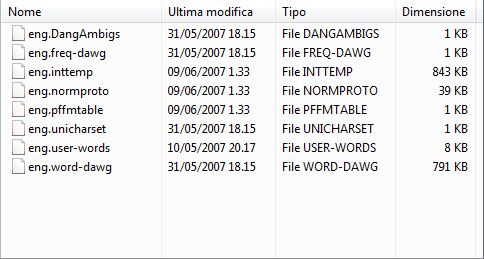
torniamo alla cartella FreeOCR ed entriamo nella sottocartella tessdata
quindi affianchiamo le due cartelle, quella del programma lasciata aperta, e quella che contiene il dizionario Italiano, quindi spostiamo i file che iniziano in ITA in quella dove ci sono i file che iniziano per ENG
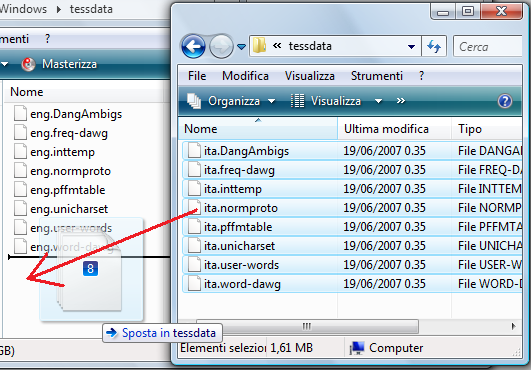
quando abbiamo spostato i file chiudiamo la cartella
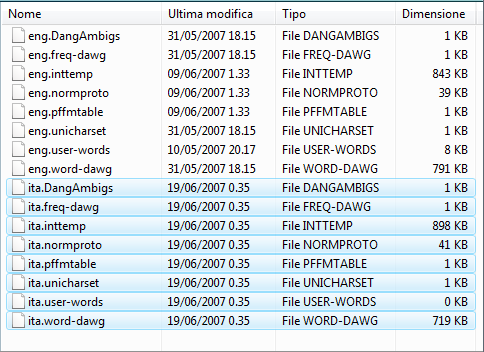
se il programma era aperto chiudiamolo e riavviamolo, in OCR Language dovete spuntare la voce ITA ogni volta che avviate il programma, non rimane memorizzato (ovviamente selezionate ITA se il documento è in ITALIANO), se vi interessano i dizionari di altre lingue cliccate questi link: Olandese - Spagnolo - Tedesco - Francese - e copiate i file come appena spiegato per la lingua Italiana
adesso siamo pronti per iniziare il lavoro, se il testo da convertire è su un'immagine (sono compatibili: TIF, BMP, JPG, GIF, PNG ) clicchiamo si Open
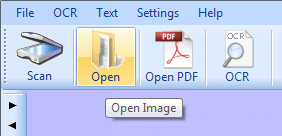
entriamo nella cartella FreeOCR sul desktop e poi su Esempi
selezioniamo il file book.tif
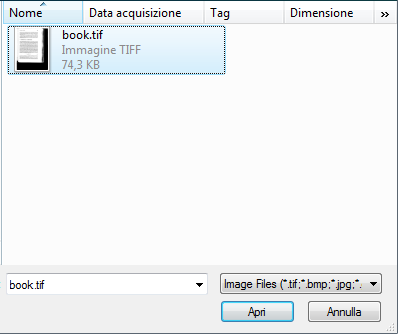
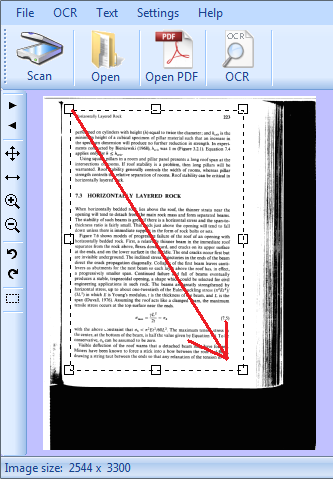
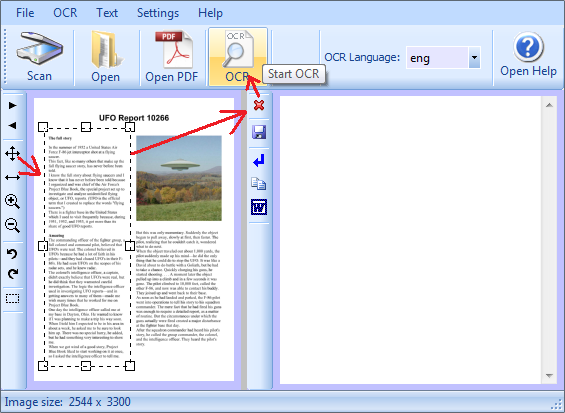
l'immagine è stata scansionata da un libro, pertanto presenta delle parti sporche fuori dal testo, in questo caso dobbiamo selezionare l'area del testo altrimenti il nero fuori verrebbe interpretato come testo e ci sarebbero molti errori
clicchiamo l'icona indicata dalla freccia
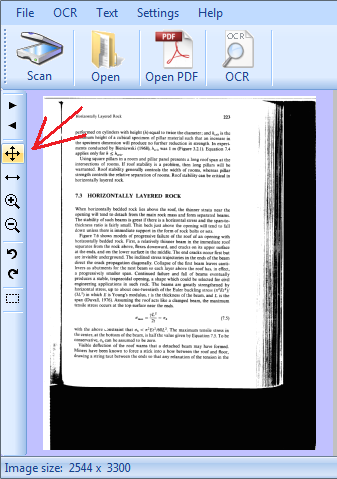
posizioniamoci con la freccia del mouse in un angolo e tenendo premuto il pulsante sinistro del mouse selezioniamo la parte del testo, quindi rilasciamo il pulsante
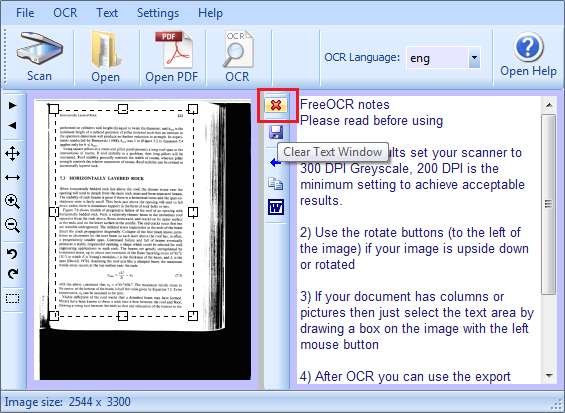
prima di procedere con la scansione clicchiamo la X rossa per eliminare il testo che compare nella finestra a destra
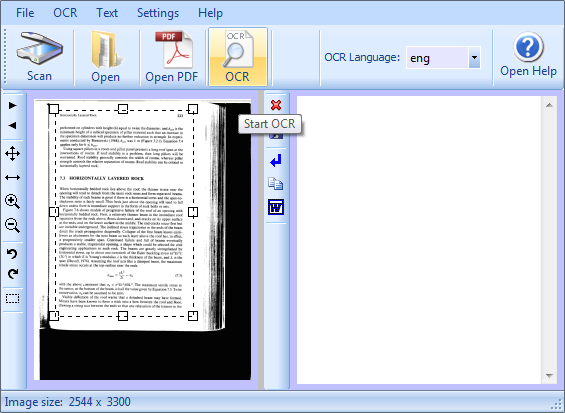
clicchiamo il pulsante OCR e attendiamo qualche secondo
ecco fatto abbiamo convertito l'immagine in testo editabile, ovviamente ci saranno degli errori che dovremmo correggere manualmente, ma e sempre meglio correggere qualche errore che batterlo sulla tastiera
ad esempio un errore da correggere è nella prima, la parola Horizontally e stata convertita in |-|orizontally, vediamo che il testo successivo e quasi perfetto a parte altri piccoli errori
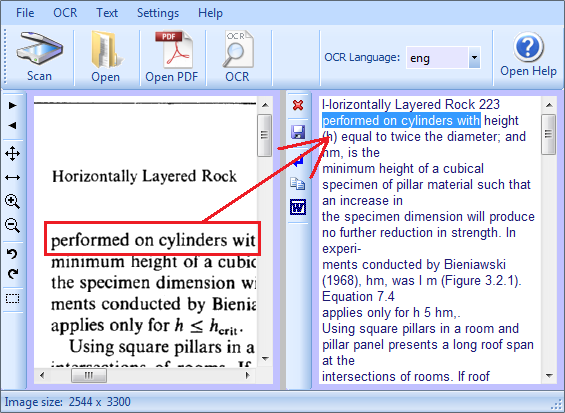
la scansione riporta il testo riga per riga e non consecutivamente, starà a noi aggiustare il testo per editarlo
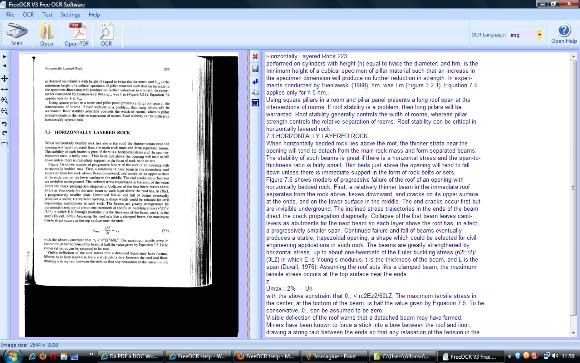
l'icona a forma di Floppy serve per salvare il testo appena convertito

cliccandola il programma ci fa salvare il testo in TXT
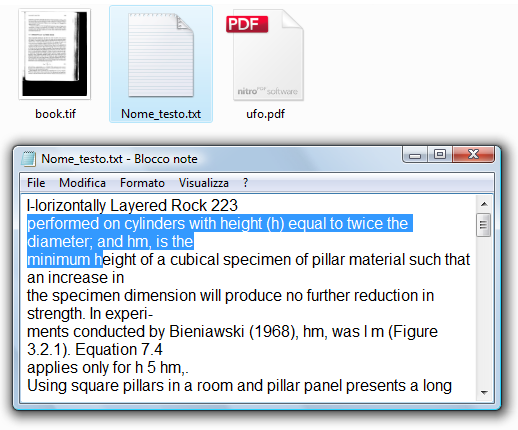
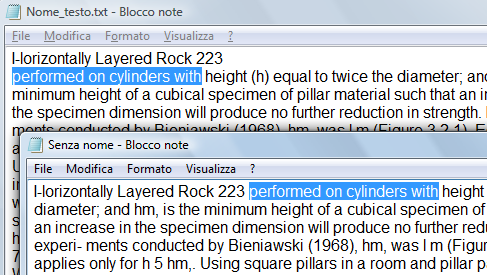
vediamo che ho aperto il testo con il Blocco Note di Windows
l'icona freccia serve per eliminare il torna a capo, questo ci evita di dover ritoccare tutte le righe per rendere il testo consecutivo,
purtroppo questo agisce su tutto il documento, ma e meglio rimandare a capo un paragrafo che eliminare i torna a capo di tutte le righe

esempio: dopo aver eliminato i torna a capo, il testo della seconda riga si affianca alla prima riga
questa icona permette di copiare il testo nella memoria del computer e di poterlo poi incollare in qualsiasi programma, per incollare il testo copiato si deve premere la combinazione tasti CTRL+V

questo pulsante salva il documento nel formato DOC di Microsoft Word

Microsoft Word con il testo della scansione
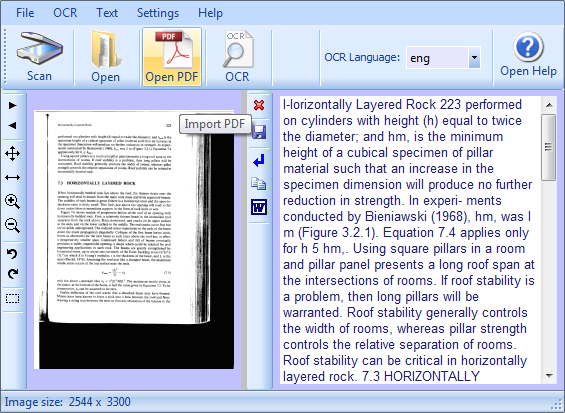
adesso vediamo come convertire i file PDF in testo, clicchiamo su Open PDF
come prima, nella cartella esempi c'è un file PDF che ho preso dal sito dell'autore, apriamolo
e come per le immagini si fa lo stesso lavoro, se il PDF contiene il testo in varie colonne, si deve selezionare una sola colonna per volta
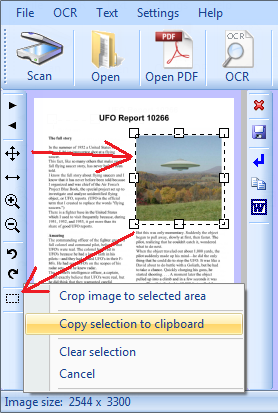
se vogliamo esportare anche le immagini contenute nel PDF, selezioniamolo e andiamo nell'ultima icona in basso, qui spuntiamo la voce Copy selection to clipborad (copia la selezione nella memoria del computer) poi andiamo nel programma dove incollare l'immagine usando la combinazione tasti CTRL+V
dal programma si può lanciare lo scanner per acquisire direttamente le pagine
ma purtroppo non ho lo scanner e non posso fare questa prova
Vi ricordo che usando lo scanner per copiare pagine di testo, dovete impostare lo scanner con la risoluzione da un minimo di 200 dpi a un massimo di 300 dpi in bianco e nero per avere un'ottima qualità di conversione, se l'immagine ha una risoluzione minore, (esempio lo schermo del computer ha una risoluzione di 72 dpi) la conversione presenterà molti errori.
Prima di scannerizzare molte pagine, fatene una e provate a convertirlo per verificare se è tutto ok.
Pagina Guida del sito del programma con traduzione in Italiano di Goole, tre pagine in totale con link in fondo alla pagina.